Spectral Clustering Algorithms
We assume that our data consists of "points" which can be arbitrary objects. We measure their pairwise similarities by some similarity function which is symmetric and non-negative, and we denote the corresponding similarity matrix by .
Unnormalized spectral clustering
Input: Similarity matrix , number of clusters to construct.
- Construct a similarity graph by one of the ways described in Section 2. Let be its weighted adjacency matrix.
- Compute the unnormalized Laplacian .
- Compute the first eigenvectors of .
- Let be the matrix containing the vectors as columns.
- For , let be the vector corresponding to the -th row of .
- Cluster the points in with the -means algorithm into clusters .
Output: Clusters with .
The normalized graph Laplacians
There are two different versions of normalized spectral clustering, depending which of the normalized graph Laplacians is used.
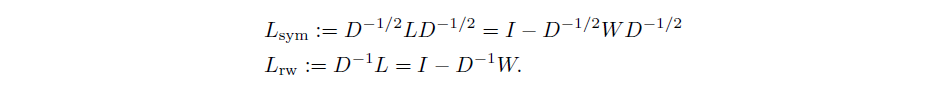 We denote the first matrix by as it is a symmetric matrix, and the second one by as it is
closely related to a random walk. In the following we summarize several properties of and .
We denote the first matrix by as it is a symmetric matrix, and the second one by as it is
closely related to a random walk. In the following we summarize several properties of and .
Normalized spectral clustering according to Shi and Malik (2000)
Input: Similarity matrix , number of clusters to construct.
- Construct a similarity graph by one of the ways described in Section 2. Let be its weighted adjacency matrix.
- Compute the unnormalized Laplacian .
- Compute the first generalized eigenvectors of the generalized eigenproblem .
- Let be the matrix containing the vectors as columns.
- For , let be the vector corresponding to the -th row of .
- Cluster the points in with the -means algorithm into clusters .
Output: Clusters with .
Note that this algorithm uses the generalized eigenvectors of , which according to Proposition 3 correspond to the eigenvectors of the matrix . So in fact, the algorithm works with eigenvectors of the normalized Laplacian , and hence is called normalized spectral clustering. The next algorithm also uses a normalized Laplacian, but this time the matrix instead of . As we will see, this algorithm needs to introduce an additional row normalization step which is not needed in the other algorithms.
Normalized spectral clustering according to Shi and Malik (2000)
Input: Similarity matrix , number of clusters to construct.
- Construct a similarity graph by one of the ways described in Section 2. Let be its weighted adjacency matrix.
- Compute the unnormalized Laplacian .
- Compute the first generalized eigenvectors of the generalized eigenproblem .
- Let be the matrix containing the vectors as columns.
- Form the matrix f rom by normalizing the rows to norm 1,that is set .
- For , let be the vector corresponding to the -th row of .
- Cluster the points in with the -means algorithm into clusters .
Output: Clusters with .
In all three algorithms, the main trick is to change the representation of the abstract data points to points . It is due to the properties of the graph Laplacians that this change of representation is useful. We will see in the next sections that this change of representation enhances the cluster-properties in the data, so that clusters can be trivially detected in the new representation. In particular, the simple k-means clustering algorithm has no difficulties to detect the clusters in this new representation.